

Nature:我叫“P值” 这是我的故事
衡量统计真实性的“黄金标准”——P值,并非众多科学家想象的那样可靠。
2010年某个瞬间,马特·莫德尔(Matt Motyl)离享受科学荣誉仅有一步之遥。那时,他发现政治极端主义者看到的世界是确实是非黑即白的。  此主题相关图片如下:1.jpg
此主题相关图片如下:1.jpg
实验结果“非常清楚”。莫德尔这样回忆道。他是夏洛茨维尔市弗吉尼亚大学的心理学博士生。他所做的一项涉及近2000人的研究中的数据似乎表明,与左翼或右翼人士相比,政治中立派能更准确地辨别不同色度的灰色。他说:“实验的假设很有趣,而且数据也能够有力支持实验假设。”用来衡量统计显著性的常用指标是P值。该实验中的P值为0.01,通常人们会认为这说明实验结果“非常显著”。莫德尔十分有把握能把自己的论文发表在高影响因子的刊物上。
但是,现实无情地粉碎了幻想。由于担心实验结果陷入再现性争论,莫德尔和他的导师布莱恩•诺塞克(Brian Nosek)决定重复实验。添加了新的数据之后,P值变成了0.59,这个数字远未达到学界一般能接受的显著性水平0.05。莫德尔观察到的心理学效应没有了,他年少成名的梦也被打碎了。
其实,不是莫德尔的数据或分析出了什么问题,而是P值这个指标出了问题。从本质上讲,这个指标出人意料的不稳定,它并不是大多数科学家想象的那样可靠和客观。“P值没有起到人们期望的作用,因为它压根就不可能起到这个作用。”伊利诺伊州芝加哥市罗斯福大学的经济学家斯蒂芬•兹利亚克(Stephen Ziliak)这样说,他经常批评统计学的应用方式。
出于对实验可重复性的担忧,P值的问题让很多科学家特别发愁。2005年,加州斯坦福大学的流行病学家约翰•埃迪尼斯(John Ioanniadis)指出,大多数公开发表的科学发现都是有问题的。此后,一连串备受瞩目的、有可重复性问题的研究迫使科学家重新思考该如何评估研究结果。
与此同时,统计学家也在寻找更好的分析数据的方法,以避免科学家错失重要信息,或在假阳性结果上浪费精力。“当你的统计思想发生改变之后,突然,重要的东西也完全变了。”斯坦福大学物理学家、统计学家史蒂文·古德曼(Steven Goodman)说:“规则并不是天注定的,它是由我们所采用的统计方法决定的。”
对P值的误用
人们一直都对P值批评不断。90年前P值诞生以来,被比作过蚊子(因为这东西烦人又挥之不去)、皇帝的新衣(因为P值的方法中到处都是显而易见却被所有人无视的问题)以及“不育的风流才子”手中的工具——这位“才子”强抢了科学佳人,却让科学佳人后继无人。一位研究人员表示,应该把“统计推论和假设检验”这个方法改个名字,叫做“统计假设和推论检验”(statistical hypothesis inference testing),大概因为这个名字的首字母缩写更符合它的气质。
讽刺之处在于,20世纪20年代,英国统计学家罗纳德·费希尔(Ronald Fisher)首次采用P值方法时,并没有打算把它作为决定性的检验方法。他本来只是用P值作为一种判断数据在传统意义上是否显著的非正式方法,也就是说,用来判断数据证据是否值得进行深入研究。P值方法的思路是先进行一项实验,然后观察实验结果是否符合随机结果的特征。研究人员首先提出一个他们想要推翻的“零假设”(null hypothesis),比如,两组数据没有相关性或两组数据没有显著差别。接下来,他们会故意唱反调,假设零假设是成立的,然后计算实际观察结果与零假设相吻合的概率。这个概率就是P值。费希尔说,P值越小,研究人员成功证明这个零假设不成立的可能性就越大。
将数据和背景知识相结合得出科学结论的过程是流动的、非数值化的。尽管P值的精确性显而易见,费希尔还是希望它只是这个过程的一部分。但是,科学家很快就开始利用P值来保证循证决策的严谨与客观。这一运动是20世纪20年代末,由费希尔的死对头、波兰数学家耶日·内曼(Jerzy Neyman)和英国统计学家埃贡·皮尔森(Egon Pearson)一手推动的。他们采用了一种新的数据分析框架,该框架中包括统计效力、假阳性、假阴性和很多其他如今在统计学概论课上耳熟能详的概念。他俩直接无视了P值这个指标。
双方争执不断,内曼批评费希尔的某些工作从数学上讲比“毫无用处”还糟糕,而费希尔对内曼的方法给出的评价是“无比幼稚”、“在西方学界中简直骇人听闻”。但是,就在双方争执不下时,其他研究人员的耐心渐渐耗尽了。他们开始给进行研究的科学家们编写统计学指南。但是其中很多作者并非统计学家,他们对两种方法都缺乏透彻的理解。结果就是他们把费希尔粗略的P值计算法硬塞进了内曼和皮尔森二人建立的规则严密的统计系统中,创造出了一种混合的方法,然后就出现了像“P值为0.05,即可将统计结果视为显著”这样的规则。古德曼说:“统计学家从没打算以现在的方式使用P值。”
“P值至上”带来的恶果
这样做的后果之一就是人们对P值的意义充满困惑。我们回过头来看一下莫德尔关于政治激进者的研究。大多数科学家看到实验最初统计结果的P值为0.01,就会认为莫德尔的结论不成立的概率只有1%。但他们错了。P值无法告诉研究人员这样的信息。P值能做的,就是在特定的零假设条件下对数据特征进行总结分析。研究人员不能利用P值通过反向推导对事实作出判断。要对事实作出判断,还需要更多信息,也就是现实世界中该效应客观存在的概率。忽视了这一点,就好像一个人清晨醒来觉得有点头痛,然后就断定自己得了某种罕见的脑瘤。这当然不是不可能,只是这事儿摊到你头上的概率太小,所以你得先拿出更多证据推翻例如过敏反应这样更为常见的原因。结论越是令人难以置信(比如心灵感应、外星人、顺势疗法),这种惊人的发现是假阳性的可能性就越大,不管你的P值有多小。
这些都是比较难懂的概念,但是一些统计学家试图用它们来解释经验法则的失灵(见下图)。根据应用最广泛的一种计算方法,如果假设为该现象存在,那么当P值为0.01时,该现象实际并不存在的概率至少为11%;而当P值为0.05时,这一概率则会上升到29%。因此,莫德尔的发现是假阳性的概率超过10%。同样,结果可重复的概率也不是大多数人所想的99%,而是73%左右。而再得到一个极为显著的结果的概率只有50%。换言之,莫德尔的实验结果不可重复的概率高得惊人,就跟抛硬币猜正面向上,而落下来是反面朝上的概率差不多。 此主题相关图片如下:2.jpg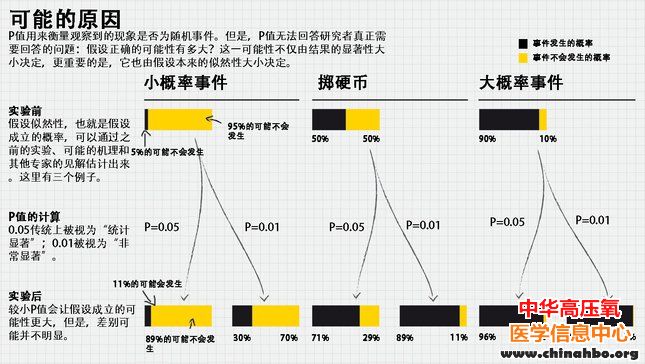
图中的三个例子证明,即使计算得出的P值非常小(具有统计显著性),实验结果也可能具有极高的不可重复率。
批评者也感慨P值会让研究人员思维混乱。最重要的一个例子是,P值容易使研究者错误的估计现象的真实影响。比如去年,一项覆盖超过19000人的研究显示,在网上结识的夫妻比在现实生活中结识的夫妻离婚的可能性更低(P<0.002),而获得婚姻满足感的可能性则更高(P<0.001)。(点击这里看详情)。这一现象也许挺让人印象深刻,但这种现象其实非常不明显。网上结识的夫妇离婚率为5.96%,而现实生活中结识的夫妻离婚率为7.67%,根据7分幸福感评分表测试中,网上结识的夫妻幸福感为5.64分,而现实生活中结石的夫妻幸福感为5.48分。澳大利亚墨尔本市拉筹伯大学的荣誉心理学家杰夫·卡明(Geoff Cumming)认为:“为了追求很小的P值而忽略背后更大的问题这一现象是“诱人的显著性”的牺牲品。”但是,显著性并不意味着实际中确实存在相关性。他说:“我们应该问的是,‘某种现象出现的概率有多大?’而不是‘有没有某种现象?’”
大概,最糟糕的错误是某种自欺欺人的行为,宾夕法尼亚大学的心理学家尤里·西蒙逊(Uri Simonsohn)及其同事给这种行为起名为“P值操纵”(P-hacking)。这种行为也被称为数据挖掘、数据窥探、数据钓鱼、追逐显著性或者双重计算。西蒙逊解释道:“P值操纵就是不断地把数据量加倍,直到获得自己想要的结果。”这种行为甚至是下意识的。这可能是在线城市词典中收录的第一个统计学词条,该词条的例句是:“这一发现似乎是通过P值操纵做出来的。作者去掉了其中一种条件下的数据,使总体的P值小于0.05。”或者“她是个P值操纵者,总是一边收集数据一边看数据好不好。”
这种行为的结果是,把本应带着质疑眼光审视的探索性研究的结果变得看似确定无疑实际上却难以重复。西蒙逊的计算机模拟实验表明,只需改变研究中的若干数据分析方法,就能使假阳性的概率提高到60%。如今的研究都希望能从杂乱的数据中发现并不十分明显的现象。在这种背景下,尤其容易出现P值操纵。尽管难以估计这种做法有多普遍,但西蒙逊认为这一问题应该已经很严重了。在一项分析研究中,他发现有迹象表明,很多公开发表的心理学论文中,P值都出人意料地分布在0.05左右——就像研究人员通过P值操纵不断尝试,直到得到理想的P值
解决之道
尽管对P值提出批评的大有人在,但统计方法的变革仍然进展缓慢。“费希尔、内曼和皮尔森提出他们的理论后,统计学的基本框架实质上没有发生任何改变。”古德曼说。1982年,明尼阿波利斯市明尼苏达大学心理学家约翰·坎贝尔(John Campell)曾经抱怨过这个问题,当时他还是《应用心理学杂志》的编辑。他说:“要把作者的注意力从P值上转移走几乎是不可能的,P值小数点后面的零越多,人们就越抓着P值不愿放手。”1989年,马萨诸塞州波士顿大学的肯尼斯·罗斯曼(Kenneth Rothman)创办了《流行病学》这本杂志,当时他尽力劝阻作者不要使用P值。但是在2001年他离开了杂志社后,这本杂志中又经常出现P值了。
埃尼迪斯最近正在PubMed数据库中搜寻数据,用来研究不同领域的学者是如何使用P值和其他统计学证据的。“只需要粗略浏览几篇最近发表的论文,你就会发现P值仍然是非常非常流行的方法。”
古德曼认为,这种根深蒂固的研究文化需要彻底的改革——人们必须改变统计学的教授方式、数据分析方式以及结果呈现和解释的方式;而好在研究人员已经开始意识到自己的问题了。“已公开发表的众多科学发现都不成立,这给人们敲了个警钟。”埃尼迪斯等研究者的研究揭示了理论统计学的批评观点与统计学应用上的难题之间的联系。古德曼说:“统计学家预言会出现的问题正是我们当前遇到的问题,只是我们还没有找到全部的解决办法。”
统计学家提出了几个或许可行的方法。比如卡明认为,为了避免掉进思考结果是否显著这个陷阱,研究人员应该在文章中提供效应量和置信区间的相关数据。这些数据可以反映P值无法反映的信息,也就是效应的规模及其相对重要性。
很多统计学家还呼吁用基于贝叶斯法则的方法替代P值。这一法则诞生于18世纪,其思想是把概率视为某种结果的似然性而非出现的频率。这其中蕴含了某种主观因素,而这也是统计学前沿学者想极力避免的。但是,贝叶斯分析框架能够使观察者相对容易地将自己所知道的内容融入结论,以及计算出现新数据后概率如何变化。
其他人则赞成一种更普遍的方法,即鼓励研究人员对同一套数据用多种方法进行分析。 卢森堡市公共卫生研究中心的统计学家史蒂芬·森(Stephen Senn)把这个方法比作没法从墙角里绕出来的扫地机器人。任何数据分析方法最终都会有行不通的时候,这时就需要用常识将分析拖回正轨。他认为倘若用不同的方法得到了不同的结论,“就表明研究者应该继续开动脑筋,努力找到原因”,而这能让我们更好地理解背后的真相。
西蒙逊认为科学家为自己辩解最有利的武器就是承认一切。他鼓励作者在论文中写上这样一段话:“论文中列出了研究中我们确定样本大小的方法、所有舍弃的数据(如果有的话)以及研究中用到的所有操作和测量方法。”通过这种方式表明文章没有进行“P值操纵”。他希望通过披露这些信息,能够阻止P值操纵行为,或者至少能提醒读者注意论文中的疑点,并自行做出判断。
纽约市哥伦比亚大学政治学家、统计学家安德鲁·格尔曼(Andrew Gelman)表示,目前另一个受到关注的类似方法是两阶段分析法,也叫做“先预定后重复法”(preregistered replication)。这种方法中,探索与验证分析通过不同的方式进行,而且要在论文中清楚地标示出来。例如,研究人员首先做两个探索性的小研究,用来发现可能比较有趣的现象,而又不需要太担心假阳性结论;而不是一下做4个单独的小研究,然后在同一篇论文中写出所有的结果。然后,在上述研究结果的基础上,作者再决定用什么方法来验证他的发现,并在Open Science Framework这样的数据库中向公众提前披露自己的研究意向。然后,他们再进行重复实验,并将结果之前与探索性研究的结果一同发表。格尔曼表示这种方法使研究分析更加自由和灵活,同时也能使研究者保持严谨,并降低公开发表的假阳性结果的数量。
古德曼还表示,进一步来说,研究人员需要意识到传统统计学方法的局限性。他们应该在研究中融入对假设似然性和研究局限性的科学判断,而这些内容通常情况下会被放到讨论部分——包括相同或类似实验的结果、研究人员提出的可能的机制以及临床认识等等。马里兰州巴尔的摩市约翰霍普金斯大学布隆伯格公共卫生学院的统计学家理查德·罗耶儿(Richard Royall)认为,科学家应该在实验结束之后思考三个问题:“支持数据是什么?”、“我应该相信什么样的数据?”以及“下一步应该怎么做?” 单一方法无法回答上述全部问题。古德曼说:“数字仅仅是科学讨论的开始,而不是结束。”
原文检索:
Regina Nuzzo. Scientific method: Statistical errors. Nature, 12 February 2014; doi:10.1038/506150a













